Updated: June 26, 2009
Not that long ago, we've had a long, extensive tutorial on GParted, a powerful and friendly partitioning software that allows you to configure your drives and partitions for installations of multiple operating systems. The tutorial helped us learn he Linux vernacular and we mastered the basic configurations, like creating, resizing, moving, and deleting of partitions, and even some more advanced stuff. In all cases, we worked with individual partitions. We did not dabble in RAID.
In the tutorial, I only briefly mentioned RAID and LVM. In both cases, GParted could display some information on these setups, but it was incapable of creating them. Moreover, being able to create RAID and/or LVM is significantly more difficult than traditional partitions. Extra knowledge and special tools are needed. I promised separate tutorials on both subjects - and here we are. Today, we will talk about RAID.
In this tutorial, we will learn what RAID is, both the acronym and the principle. We will learn what different types of RAID exist and what their advantages/disadvantages over conventional single disk/partition setups are. We will then install (Ubuntu) Linux by configuring two different types of RAID on the local hard disks. This experience will expose to the delicate process of partitioning once again, with emphasis on RAID devices and notation. In particular, we will also learn how the standard Linux bootloader (GRUB) handles the RAID devices. Lastly, we will learn about administrative system utilities used to control and manipulate RAID devices on Linux systems.
Quite a lot - and as always, step-by-step, with lots of images and in great detail, no steps skipped or assumed, with real life examples throughout. I believe this article will help you gain crucial skill and knowledge to be able to use Linux + RAID with great confidence. Let us begin.

Table of Contents:
- Tools of the trade
- Introduction
- RAID levels
- RAID notation
- Working with RAID - real-life examples
- Installation
- After installation
- RAID & GRUB
- GParted & RAID
- Advanced configurations
- Other
- Conclusion
Tools of the trade
Throughout this tutorial, I will demonstrate with Ubuntu 8.10 Intrepid Ibex, installed using the Alternate CD, as the classic desktop install CD does not have the ability to create RAID devices and install to them.
While Intrepid is no longer the most current Ubuntu release currently, please note that the choice does not really matter, which is why I deliberately decided to use. I want you to be able to use the power of your knowledge without sticking to brands. I want you to be able to understand the principle. Once you get the hang of things, the choice of the operating system will become transparent. The only difference will be a slight cosmetic chance between distros and/or release.
That said, I will also demonstrate RAID installation and the subsequent configuration in several other distributions, in a sort of addendum article to this tutorial. In this sequel, I will cover the RAID configuration in openSUSE - and some other distros - just to show you that once you learn the idea, it will not matter which software you use. Pretty much like driving a car.
Additionally, we will also use several command line tools particular to RAID, which come included with most Linux distributions.
Now, let's start.
Introduction
RAID stands for Redundant Array of Inexpensive Disks. This is a solution where several physical hard disks (two or more) are governed by a unit called RAID controller, which turns them into a single, cohesive data storage block.
An example of a RAID configuration would be to take two hard disks, each 80GB in size, and RAID them into a single unit 160GB in size. Another example of RAID would be to take these two disks and write data to each, creating two identical copies of everything.
RAID controllers can be implemented in hardware, which makes the RAID completely transparent to the operating systems running on top of these disks, or it can be implemented in software, which is the case we are interested in.
Purpose of RAID
RAID is used to increase the logical capacity of storage devices used, improve read/write performance and ensure redundancy in case of a hard disk failure. All these needs can be addressed by other means, usually more expensive than the RAID configuration of several hard disks. The adjective Inexpensive used in the name is not without a reason.
Advantages
The major pluses of RAID are the cost and flexibility. It is possible to dynamically adapt to the growing or changing needs of a storage center, server performance or machine backup requirements merely by changing parameters in software, without physically touching the hardware. This makes RAID more easily implemented than equivalent hardware solutions.
For instance, improved performance can be achieved by buying better, faster hard disks and using them instead of the old ones. This necessitates spending money, turning off the machine, swapping out physical components, and performing a new installation. RAID can achieve the same with only a new installation required. In general, advantages include:
- Improved read/write performance in some RAID configurations.
- Improved redundancy in the case of a failure in some RAID configurations.
- Increased flexibility in hard disk & partition layout.
Disadvantages
The problems with RAID are directly related to their advantages. For instance, while RAID can improve performance, this setup necessarily reduces the safety of the implementation. On the other hand, with increased redundancy, space efficiency is reduced. Other possible problems with RAID include:
- Increased wear of hard disks, leading to an increased failure rate.
- Lack of compatibility with other hardware components and some software, like system imaging programs.
- Greater difficulty in performing backups and system rescue/restore in the case of a failure.
- Support by operating systems expected to use the RAID.
Limitations
RAID introduces a higher level of complexity into the system compared to conventional disk layout. This means that certain operating systems and/or software solutions may not work as intended. A good example of this problem is the LKCD kernel crash utility, which cannot be used in local dump configuration with RAID devices.
The problem with software limitations is that they might not be apparent until after the system has been configured, complicating things.
To sum things up for this section, using RAID requires careful consideration of system needs. In home setups, RAID is usually not needed, except for people who require exceptional performance or a very high level of redundancy. Still, if you do opt for RAID, be aware of the pros and cons and plan accordingly.
This means testing the backup and imaging solutions, the stability of installed software and the ability to switch away from RAID without significantly disrupting your existing setup.
RAID levels
In the section above, we have mentioned several scenarios, where this or that RAID configuration may benefit this or that aspect of system work. These configurations are known as RAID levels and they govern all aspects of RAID benefits and drawbacks, including read/write performance, redundancy and space efficiency.
There are many RAID levels. It will be impossible to list them all here. For details on all available solutions, you might want to read the Wikipedia article on the subject. The article not only presents the different levels, it also lists the support for each on different operating systems.
In this tutorial, we will mention the most common, most important RAID types, all of which are fully supported by Linux.
RAID 0 (Striping)
This level is achieved by grouping 2 or more hard disks into a single unit with the total size equaling that of all disks used. Practical example: 3 disks, each 80GB in size can be used in a 240GB RAID 0 configuration.
RAID 0 works by breaking data into fragments and writing to all disk simultaneously. This significantly improves the read and write performance. On the other hand, no single disk contains the entire information for any bit of data committed. This means that if one of the disks fails, the entire RAID is rendered inoperable, with unrecoverable loss of data.
RAID 0 is suitable for non-critical operations that require good performance, like the system partition or the /tmp partition where lots of temporary data is constantly written. It is not suitable for data storage.
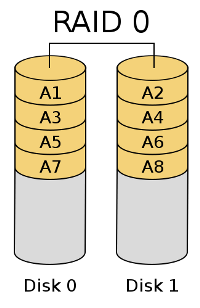
Note: Image taken from Wikipedia, distributed under GFDL.
{kind=link}
RAID 1 (Mirroring)
This level is achieved by grouping 2 or more hard disks into a single unit with the total size equaling that of the smallest of disks used. This is because RAID 1 keeps every bit of data replicated on each of its devices in the exactly same fashion, create identical clones. Hence the name, mirroring. Practical example: 2 disks, each 80GB in size can be used in a 80GB RAID 1 configuration. On a side note, in mathematical terms, RAID 1 is an AND function, whereas RAID 0 is an OR.
Because of its configuration, RAID 1 reduced write performance, as every chunk of data has to be written n times, on each of the paired devices. The read performance is identical to single disks. Redundancy is improved, as the normal operation of the system can be maintained as long as any one disk is functional. RAID 1 is suitable for data storage, especially with non-intensive I/O tasks.
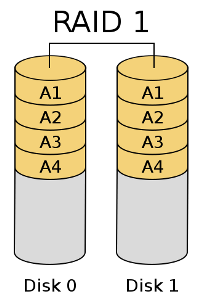
Note: Image taken from Wikipedia, distributed under GFDL.
{kind=link}
RAID 5
This is a more complex solution, with a minimum of three devices used. Two or more devices are configured in a RAID 0 setup, while the third (or last) device is a parity device. If one of the RAID 0 devices malfunctions, the array will continue operating, using the parity device as a backup. The failure will be transparent to the user, save for the reduced performance.
RAID 5 improves the write performance, as well as redundancy and is useful in mission-critical scenarios, where both good throughput and data integrity are important. RAID 5 does induce a slight CPU penalty due to parity calculations.

Note: Image taken from Wikipedia, distributed under GFDL.
{kind=link}
Linear RAID
This is a less common level, although fully usable. Linear is similar to RAID 0, except that data is written sequentially rather than in parallel. Linear RAID is a simple grouping of several devices into a larger volume, the total size of which is the sum of all members. For instance, three disks the sizes of 40, 60 and 250GB can be grouped into a linear RAID the total size of 350GB.
Linear RAID provides no read/write performance, not does it provide redundancy; a loss of any member will render the entire array unusable. It merely increases size. It's very similar to LVM. Linear RAID is suitable when large data exceeding the individual size of any disk or partition must be used.
Other levels
There are several other levels available. For example, RAID 6 is very similar to RAID 5, except that it has dual parity. Then, there are also nested levels, which combine different level solution in a single set. For instance, RAID 0+1 is a nested set of striped devices in a mirror configuration. This setup requires a minimum of four disks.
These setups are less common, more complex and more suitable for business rather than home environment, therefore we won't talk about those in this tutorial. Still, it is good to know about them, in case you ever need them.
Summary
So, let's review what we've learned here. We have four major RAID levels that interest us, each offering different results. The most important parameters are the I/O performance, redundancy and space efficiency.
A few words on the table below:
# devices: this column defines the minimum number of devices required to create such a setup.
Efficiency: this term denotes how "well" the array uses the available space. For example, if the array uses all available space, then its efficiency is equal to the total number of devices used. For instance, a RAID 0 with four 80GB disks will have a total space of 320GB, in other words, 4 x 80GB - or simply: 4 (n).
Attrition: this tells us how many devices in the array can be lost without breaking the functionality of the array and losing data.
Here's a small table showing the differences between the four levels discussed above:
| Level | #devices | Efficiency | Attrition |
| RAID 0 | 2 | n | 0 |
| RAID 1 | 2 | n/2 | n-1 |
| RAID 5 | 3 | n-1 | 1 |
| Linear | 2 | n | 0 |
RAID notation
We also have to talk about how RAID devices are seen and marked by Linux. In fact, compared to hard disk notation, which takes into consideration a lot of parameters like disk type and number, partition type, etc, RAID devices are fairly simple.
RAID devices are marked by two letters md and a number. Example: md0, md3, md8. By themselves, the RAID device names tell us nothing about their type. In this regard, the RAID notation is lacking compared to disk/partition notation.
To be able to get more information about our RAID devices, we need additional tools. We will talk about these tools in greater detail later. For now, here's just a snippet of information.
/proc/mdstat
/proc is a pseudo-filesystem on modern Linux operating systems. The term pseudo is used here, because /proc does not monitor a data structure on the disk; instead, it monitors the kernel. In other words, /proc is a sort of a windows into kernel, providing live information about the system internals, at any given moment.
Many parameters about the operating system can be extracted from different files under the /proc tree. For instance, we can check all the running processes and their memory maps, we can check CPU information, mounts, and more. We can also check the status of our RAID devices.
This is done by printing out the contents of the mdstat file under /proc.
If there are any RAID devices present, they will be printed out to the screen (STDOUT).
Here's an example:

What do we have here? Let's take a look at the first listed device, md1:
Personalities: [raid1]
This line tells us which types of RAID arrays are used on the system. In this case, we have a single one.
md1: active raid1 sdb2[1] sda2[1]
md1 is a RAID 1 (mirror) device, spanning sda2 and sdb2 partitions. This device is active and mounted. If it were not used, it would have been listed under unused devices further below.
513984 blocks [2/2] [UU]
The second line gives us some more information about the device. [2/2] [UU] tells us both partitions are used. This may seem a little strange, but it is not. Some RAID configurations can continue functioning even if a number of devices are disabled (failed), either deliberately or due to an error or disk problem. The RAID device would still exist, but parts thereof would no longer be functioning properly.
In our case above, we have 2 out of 2 devices working, in which case the [UU] is a redundant bit of information. However, what if we had [1/2] situation? This means one of the partitions has malfunctioned. To know which one, we need to look at the second pair of square brackets, which will tell us the device that still works.
As an exercise, we will deliberately fail one of our devices later, to demonstrate this.
Using cat /proc/mdstat is the fastest, simplest indication of the health and status of the RAID arrays. If there are no RAID arrays on the system, the output of the command would return output like this:

mdadm
This is a very important, powerful Linux software RAID management utility. It has no less than seven modes of operation, which include assemble, build, create, monitor, grow, manage, and misc. mdadm is a command-line utility and requires super-user (root) privileges.
Later on, we will use it to manipulate our RAID arrays.
For now, here's a quick example:

What do we have here?
- --create tells mdadm to create a new RAID device.
- --verbose tells it to print information about its operations.
- /dev/md0 is the new RAID device that we want to create.
- --level=raid1 defines the RAID level; in our case, RAID 1 (Mirror).
- --raid-devices=2 specifies how many disks (devices) are going to be used in the creation of the new RAID device.
- /dev/sda1 /dev/sdb1 are the two disks that are going to be used in the creation.
Simple, right?
OK, now that we know what RAID is and how it works, let's configure one - or two!
Working with RAID - real-life examples
In this section we will install a complete Linux operating system from scratch, with RAID 0 and RAID 1 used on the partitions on two local hard disks. We will also tackle the questions on how these devices are created and grouped, how the system identifies and uses them, and how the GRUB bootloader fits into the picture.
I will demonstrate the configuration of RAID using Ubuntu 8.10 Intrepid Ibex as the test platform. As mentioned earlier, Ubuntu 8.10 is no longer the most current release - and this does not matter one bit. The general idea remains the same - and this is what I want you to learn: the principle. Once you grasp the fundamental concepts of RAID setup, you will be able to this on any which operating system.
Furthermore, configuring RAID on Ubuntu is a good choice for several more reasons:
- Ubuntu is the most popular Linux desktop distro, which probably means there's a fair chance you will indeed be setting up RAID on Ubuntu or one of its flavors.
- The default Ubuntu installation is very simple; so simple, in fact, that is strips away some of the features for the sake of simplicity. One of the victims is indeed RAID, which cannot be configured using the standard installation from the live CD. You need the Alternate CD, which uses a text-driven installation menu and allows you to setup RAID, as well as other advanced options. The text installers looks "old" - meaning you will not really feel like you're installing Ubuntu. This will help you understand the concept beyond colors and pretty menus, allowing you to transition to other distributions with ease.
- The use of an older release and the Alternate CD allows me to prove a point: that no matter which distribution you choose, the power of Linux can be unleashed to the fullest. You do not have to disqualify distros on the premises of being "too simple" or "dumbed down" simply because such propositions are untrue.
All right, now that you know what we're up to, let's begin.
Installing Ubuntu via Alternate CD is similar to almost every Linux installation you have seen or tried or read about. Place the CD into the CD tray, boot, follow instructions.
Partitioning
After a while, you will reach the Partition Disks stage. This is where the fun begins. We will choose the manual method.
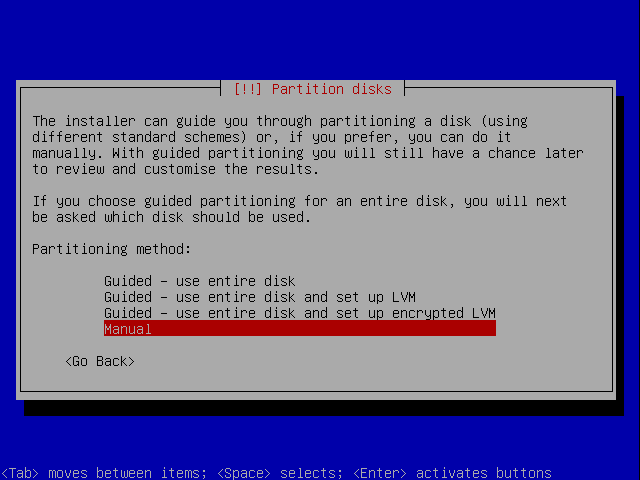
You will see the existing setup, if any. In our case, we have two hard disks, roughly identical, each with three partitions on it. Each disk holds a primary ext3 partition and a 500MB swap and a ~2GB ext3 partition inside the Extended volume.
This means we have quite a bit of freedom when it comes to creating RAID arrays, where the logic beckons to pair sda1 with sdb1, sda5 with sdb5 and so forth.

Edit partitions
To do that, we need to change the partitions. Highlight any and hit Enter. The installer will graciously tell you that You are editing ... This partition is formatted with ..., so there are no mistakes.
We need to change the Use as: field.

Change type to RAID
We will change the type to: physical volume for RAID.
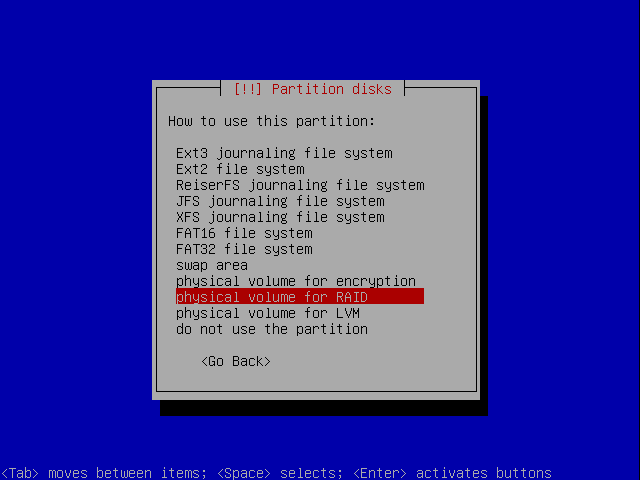
We will repeat this for all our partitions. The final layout should be something like this:

Once you do this, a new category will show up in the menu. At the beginning you only had Guided partitioning and Help on partitioning. Take a look above if you don't remember. Now, there's a new one: Configure software RAID.
The installer now recognizes the partitions flagged as RAID volumes and can now configure them.
Configure software RAID
The first thing, you will receive a warning. It tells you the changes you have just made will be committed. Furthermore, no additional changes will be allowed. Make sure you are satisfied with your layout before proceeding.
What is going to happen is that the RAID superblock is going to be written on the devices, marking them with a higher order hierarchy than just physical partitions. This will allow the operating system as well as RAID utilities to properly handle these devices.

After that, the next step is to create a new MD device. By the way, earlier, we mentioned the mdadm utility. One of its mode is the ability to create MD devices. In fact, this is exactly what is happening underneath the hood. Later, we'll see the text command that do the same job as the installer above.
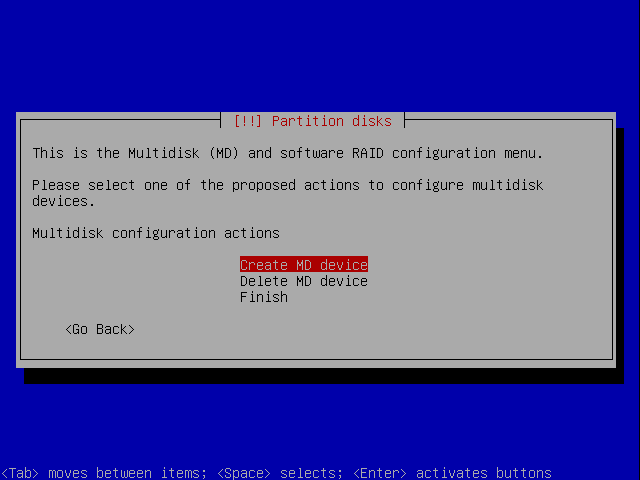
Create MD device
Choose Create MD device:
Choose device type
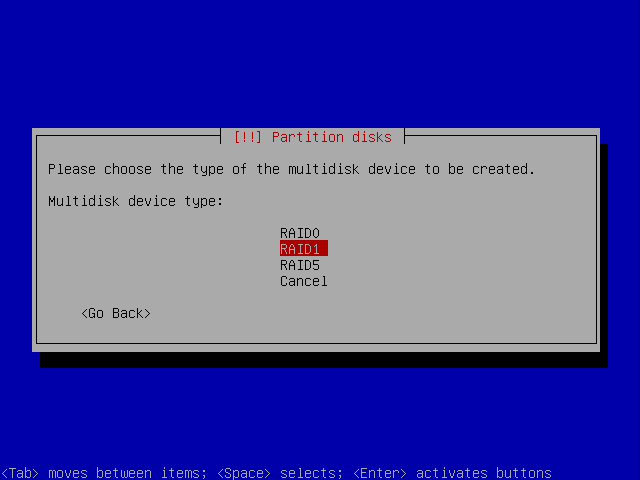
The next step is to choose the RAID type. This is a step where some thorough thinking is needed. You need to ask yourselves what are you trying to achieve?
I'm going to do the following:
- Create a RAID 1 (mirror) device called md0 and later use it as root (/). This will slow down the performance, but ensure reliability.
- Create a RAID 0 (stripe) device called md1 and use it as swap. We'll both benefit from a performance boost and increased total size. No need to worry about reliability here.
- Create a RAID 0 (stripe) device called md2 and use it as home (/home). This will allow me to have a larger home directory than individual partitions allow. Likewise, it should improve the performance.
Optimally, RAID 0 devices should be physically located on separate partitions, so that I/O operations can benefit from seeks by multiple disk heads. Furthermore, RAID 1 devices should exist on separate drives, to ensure reliability.
In our case, we're using partitions, which are only parts of physical disks, making the decisions regarding performance and reliability trickier. But if you're using whole disks as single partitions, then the classic rules for RAID configurations fully apply.
This layout may not suit you at all. You may want performance for / and reliability for /home, so you may want to use a different layout. Or you may want to create a linear array for swap, because it does not really matter how you use it, as it's a raw device.
So, our first device will be a RAID 1.
Choose number of devices
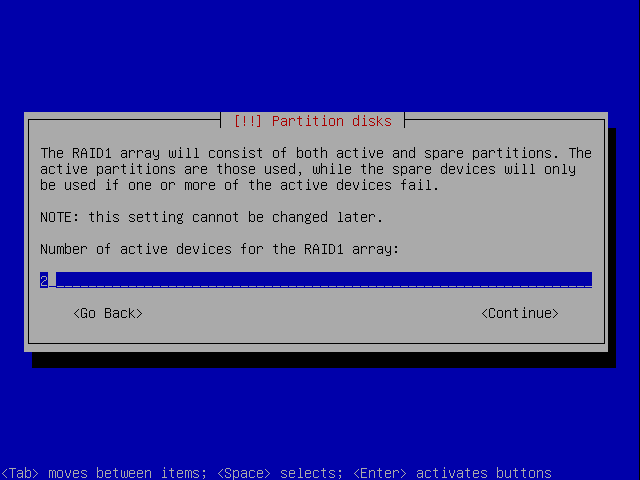
We need to decide how many (active) devices will participate in the mirror. We'll go for two.
Choose spares
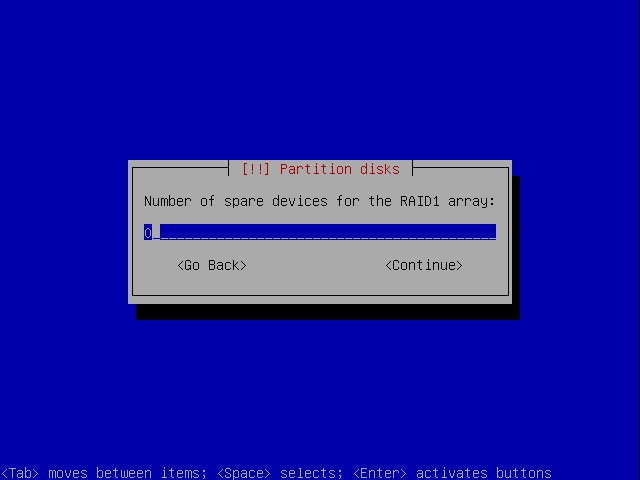
The next step is to choose spares. We need none, so it's 0.
Choose devices
Now, we need to select which devices (those marked as RAID), we want to use. For the first device, we'll use sda1 and sdb1.
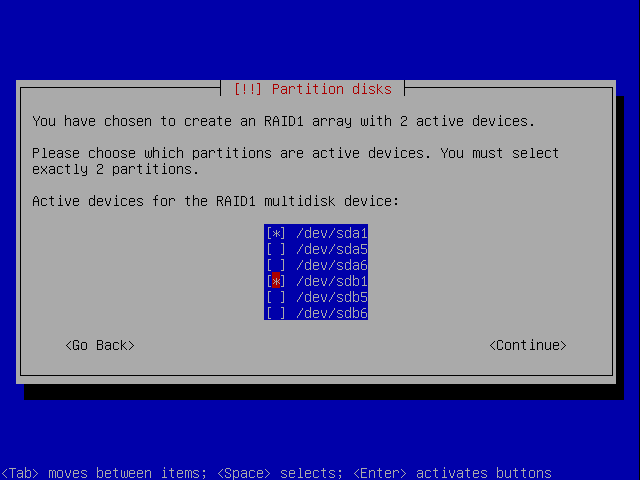
Similarly, we'll repeat the procedure for the other two devices. Our swap will be a stripe, as we want performance and no redundancy is needed.

And the last device, again a stripe:
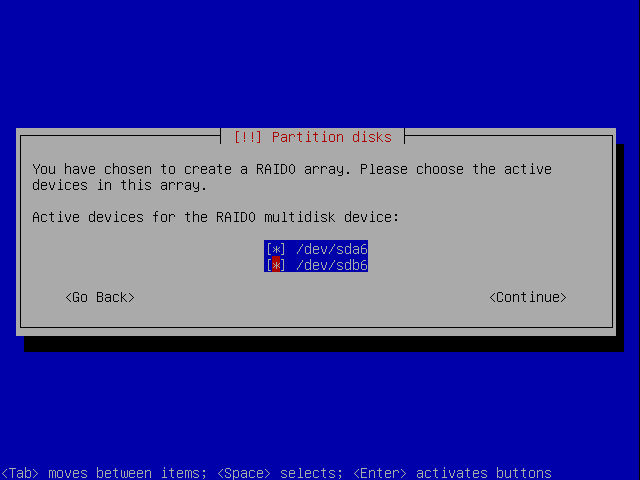
Final layout
This is what we have:

Configure mount points
Now, for all practical purposes, the md devices are just like any other partition. We need to format them and configure the mount points.
Configure root
We'll configure the root first:

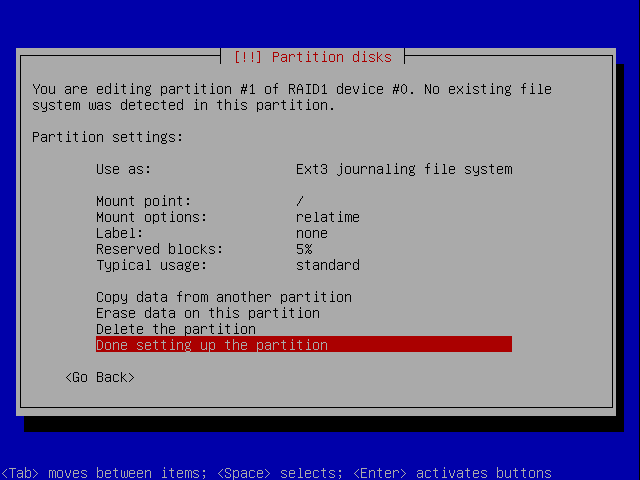
We'll repeat the same procedure for the other two partitions, swap and /home. Our final layout is now as follows:

We have everything configured as we wanted. Our devices are ready. The root partition will reside on a mirror device (md0), formatted as ext3. The md1 (stripe) will be used as swap. The home partition will reside on a stripe device (md2), formatted as ext3.
Undo / Commit
If you're satisfied, you can commit the changes - OR - undo the operations and start over.
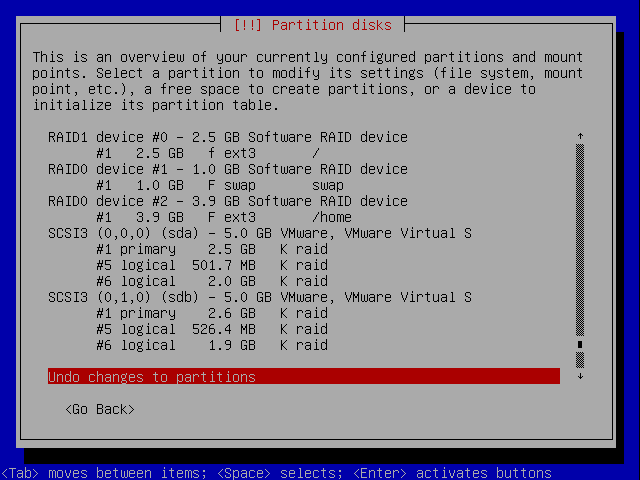
You will have to confirm your choices, in case you decide to commit them:

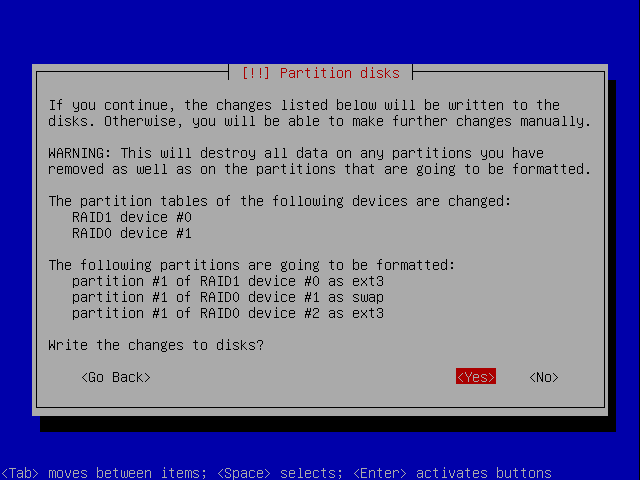
Installation
We can begin the installation.

You can now reboot and start enjoying your new system. What about the GRUB bootloader, you're asking? Well, nothing special. We'll see what happens after the boot.
After installation
Our system booted up fine, as expected.
However, some of you may have read online that GRUB cannot install properly on RAID devices and that a manual intervention may be needed in order to make sure the system is bootable. This is partially true, and I will soon show you why.
Before that, let's see what RAID looks like inside a working system:
/proc/mdstat
Let's take a look what mdstat reports:
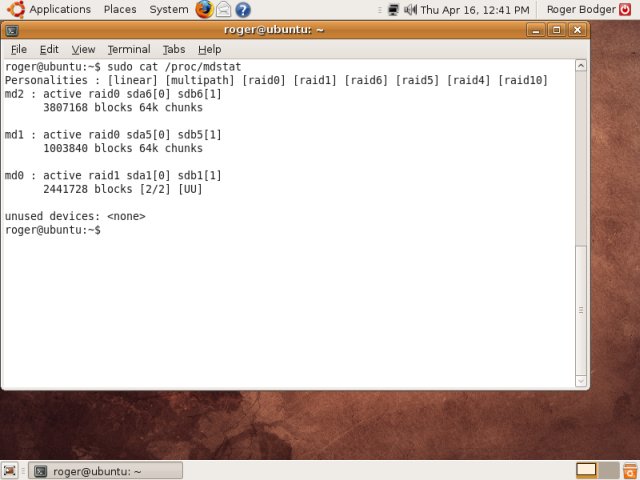
Since we're using more than one type of RAID, the list of Personalities is now longer.
Another interesting bit of information is that md1 and md2, both stripes, do not have any information inside square brackets. This means that they have no redundancy. If any of the components of their arrays goes bad, the arrays will fail. md0, on the other hand, is a mirror, and has redundancy, which is manifested in the status of healthy, used devices.
This also tells us another bit of information: we can manipulate mirror devices in vivo, but persistent changes for RAID 0 type devices will require a reboot to take effect. Let's take a look at what fdisk reports.
fdisk
fdisk is a handy partitioning utility for Linux. We've seen it in the GParted tutorial; it allows us to manipulate partitions from the command line. We can see that fdisk properly reports the RAID devices for all our partitions.

df
df reports file system disk usage. It also works with RAID devices and can tell us how much free space we have left on our partitions. Used with flags -l (local) and -h (human), it will report back for local partitions in human readable format (MB/GB):
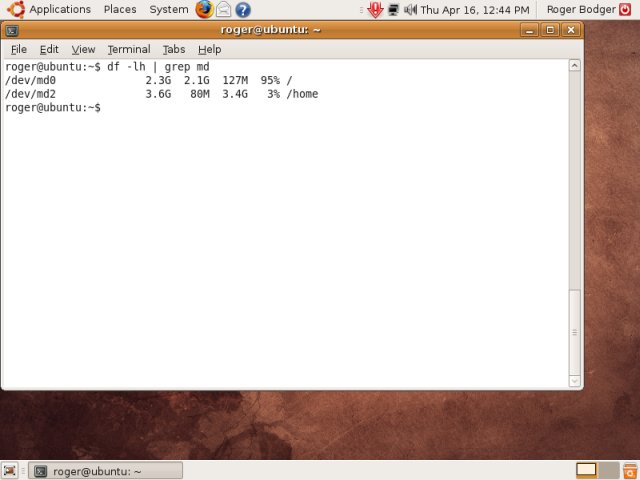
We can't see swap anywhere, though. So we need another utility to check it. We'll use swapon.
swapon
swapon (and its sister swapoff) is used to start swap on files/devices, and display status of currently used swap areas. swapon -s will display all used swap areas, their type, size, usage, and priority.
As you can se below, we have a 1GB swap device /dev/md1, which consists of two physical partitions (sda5 and sdb5) in a stripe configuration.

RAID & GRUB
Here comes the big question, how does GRUB fit into the RAID picture? Before we can answer that question, you need to read my GRUB tutorial. Once you understand how GRUB works, you'll be able to ponder the question raised here. I'm sorry, but it's a must.
Throughout this section, I will assume you have read the very long, thorough and detailed GRUB tutorial.
Basically, GRUB is a bootloader that allows multiple operating systems to be run on the same system. GRUB works by placing a piece of its code into the Master Boot Record (MBR) and tells the system where to look for configuration files on which operating system to boot.
When you're using the conventional partitioning layout, the configuration is simple. GRUB is installed to the device sector 0 and that's it. For instance, GRUB is installed to sda. End of story.
When you're using RAID for the root partition, there is more than one device involved. The question is, where does GRUB go? sda? sdb? Both?
The answer depends on the type of RAID you want. I used mirror for the root partition, which means we have two identical copies of everything on the system, including the sector 0, which contains GRUB stage 1. Therefore, we elegantly avoid the question. GRUB is installed on both devices. Reading any which MBR on either disk provides us with the whole set of information required to boot the system.
We can confirm this by looking for stage1 (using the find command in GRUB menu):
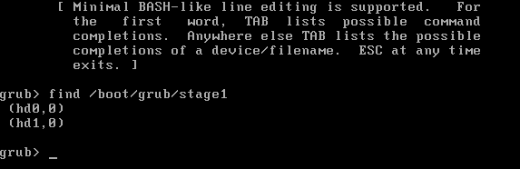
We'll talk about what happens if RAID 0 is used a little later on.
GRUB menu
The second question is, what about the GRUB menu?
Let's take at the GRUB menu. GRUB menu, part of GRUB stage2, is usually located on the /boot or / partition of the first boot device, inside grub directory.
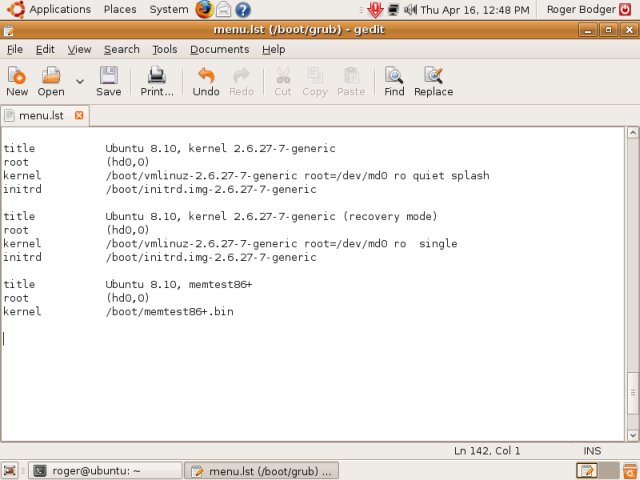
As you can see, GRUB menu takes into consideration the higher hierarchy of RAID. The root is called from an MD device and not the underlying hd/sd devices. For all practical purposes, the setup is completely transparent when it comes to stage2. The only thing we need to concern ourselves is stage1 that goes into MBR.
So, let's go back to the first question. Where does GRUB go? The best way for you to understand and solve this problem is to treat RAID devices as your partitions. GRUB needs to be in the MBR of the first boot disk. As simple as that.
This means that if you're using RAID1, there are no issues, as the sector exists "equally" on all RAID array devices. If you're using a configuration where only partial information exists on each device (like RAID0 or RAID5), the system will not be able to deduct the whole of information by reading the MBR on just one device.
So, the answer is: you will have to install GRUB on all RAID devices. If you're using a mirror configuration, this is done for you. If you're using stripe, you'll have to do it manually.
Install GRUB manually on RAID devices
You can do this in several ways: using a utility like Super Grub Disk (the easy way) or manually (the hard way) from a live CD utility. The best thing to do would be to do this after the installation is complete, before rebooting.
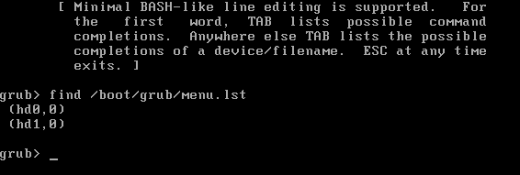
The sequence of steps required to accomplish the task is very simple. First, you'll have to find all available stage1. Then, you will have to setup GRUB into each one of them. That's all! So, let's look for stage1. This needs to be done from a live CD environment or during a GRUB boot:
We've seen what the answer looks like above:
If all the devices included in the array get listed, you're ok. If not, you will have to install GRUB on each one. For each device listed above, perform the following steps:
setup (hdX)
The values X and Y take the disk number and partition number where the root is installed. For example, in our case, we have the root partition on sda1 and sdb1. This means that we have to run the commands for (hd0,0) and (hd1,0).
Do not be tempted to look for menu.lst, because this one is deceiving. You might get a "right" answer that it is located on both partitions, but stage1 might not be installed properly.
You can also "brute-force" your way with grub-install command, if you know where the root is expected to be. For more details how to do this, please refer to the GRUB tutorial.
Summary
So, what do we have here?
- If you're installing RAID 1 (mirror), GRUB setup will be transparent to you.
- If you're installing RAID 0 (stripe), you will have to manually installed GRUB as demonstrated above.
Alternatively, you may also want to setup a small (~100-200MB) boot partitions in the classic way, then use RAID for other partitions. This is similar to what Fedora does with its LVM. A small sda1 boot is used and LVM is spread on sda2.

Which brings us to GParted ...
GParted & RAID
In the GParted tutorial, we've seen that GParted can see RAID devices, but it cannot manipulate them. Here's a screenshot of our current setup:

Notice the raid flag. Furthermore, notice the unknown filesystem on sda6. This is because we're using stripe and the information contained on the partition is only half the picture. The other half is located on sdb6. Therefore, GParted is unable to identify the filesystem properly. GParted is a powerful tool, but it is unsuitable for handling RAID.
Advanced configurations
We've seen a lot of work done, but we did not see any commands executed. Which is OK. For most people, for most practical purposes, RAID should be transparent. However, if you want to be able to control your RAID at all times, you will have to muck your hands a bit in the command line hocus pocus.
mdadm
mdadm is a powerful command-line utility to managing RAID devices. It has seven modes of operation, which include assemble, build, create, monitor, grow, manage, and misc. So let's see how we can use mdadm to achieve what we did above.
Create MD device
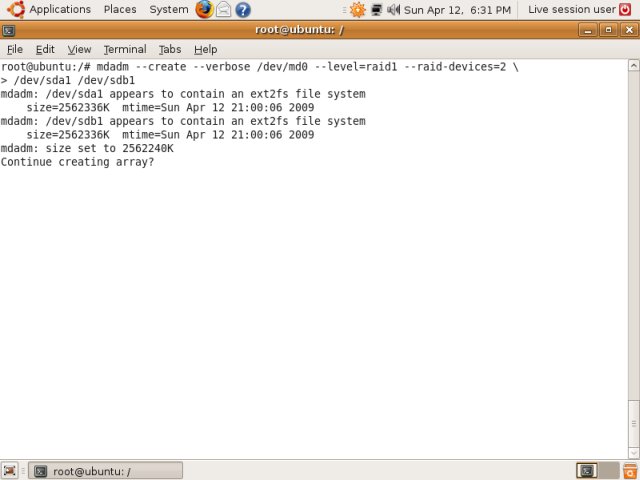
Remember the wizard we ran through when we created our mirror array on md0? Well, here it is, in text form:

Let's disassemble the command and see what it means:
-> --raid-devices=2 /dev/sda1 /dev/sdb1
We are creating a new device called /dev/md0. It is a RAID 1 device with 2 devices in it, sda1 and sdb1. Simple eh?
After you hit Enter, you'll see the device created and then synced. The synchronization is the process that takes after the RAID devices are created. Effectively, it creates the required data structure on all RAID devices.
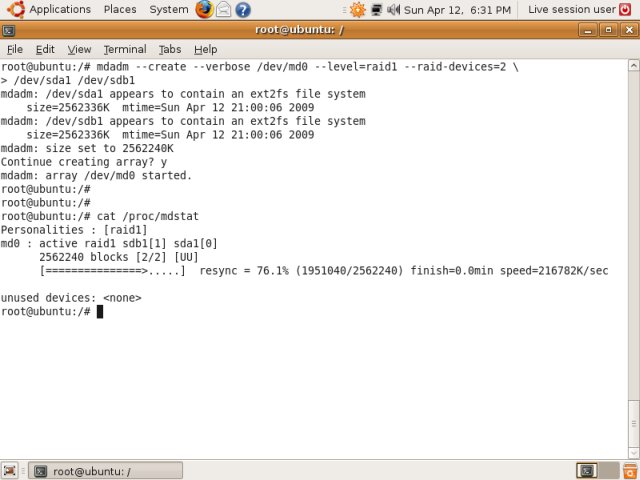
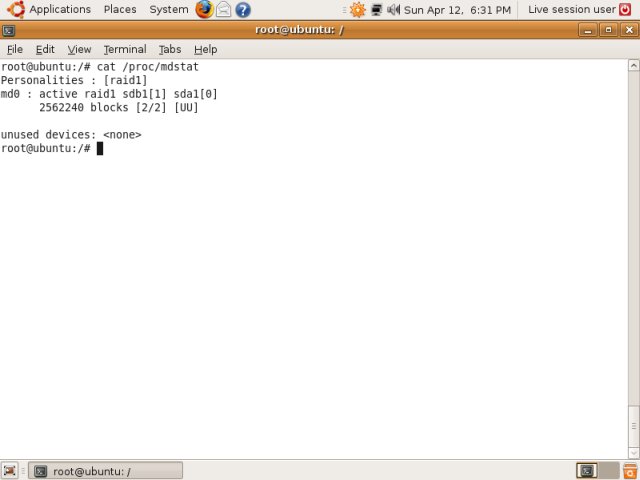
If we check mdstat, we see the old familiar picture:

Similarly, we can stop RAID devices, fail them, assemble them, and so forth. Mastering the mdadm utility takes time, but it gives you a lot of power and freedom when it comes to using Linux software RAID.
Fail/remove device
If you want to break apart a RAID, you will first have to fail its members and then remove them. On active partitions used by the operating systems, this may not be possible in-vivo and will require a reboot.
Here's an example where we fail a device:
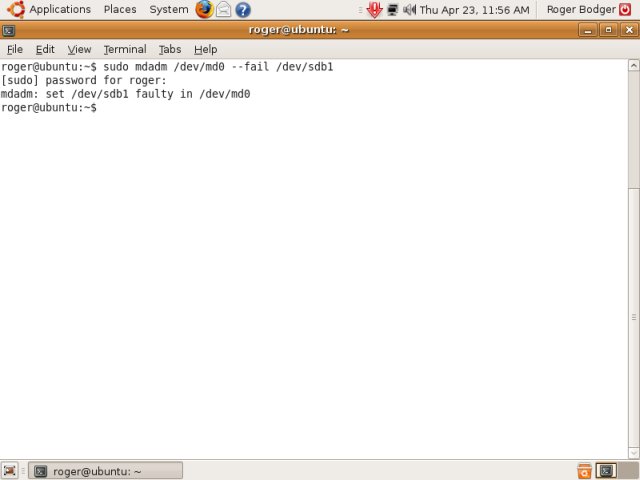
And when we print /proc/mdstat, we can now see that our targeted RAID device no longer uses both its members. The information in square brackets has changed. We only have one used device, with the other set as faulty. [2/2] now shows [2/1] and [UU] now shows [U_], indicating the second device (listed on the right) is no longer being used, as it has been set as faulty. In reality, this might happen should the disk die or a partition get corrupted for some reason.
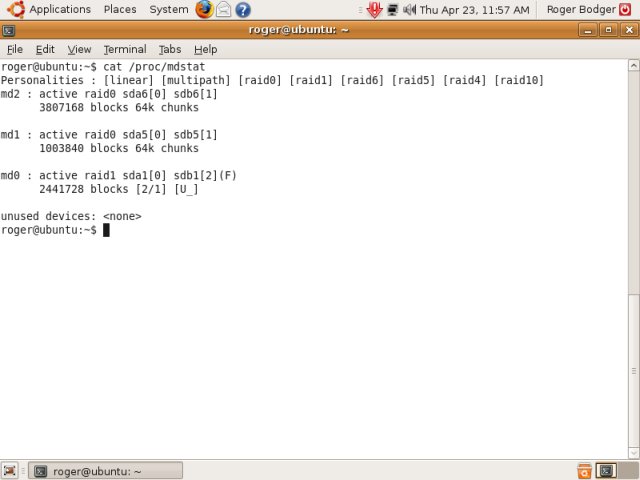
After that we can remove it ... and then, for fun, re-add it. Here's a screenshot showing the recovery progress after sdb1 was re-added. The RAID device is being rebuilt, with the data from sda1 being cloned over to sdb1.

For more details, please read the man page for mdadm.
Other
In general, there are several things you should consider before deploying RAID. These concern the cost, safety, performance, but also software compatibility.
You may need to check whether your imaging software, if you're using one, that is, is compatible with RAID devices. Just like when we configured partitions with GParted, we had to manually change the Inode size for our Ubuntu installation to make the partitions compatible with Acronis True Image software, which requires Inode size of 128 bytes.
With RAID, similar adjustments may be required.
Plan ahead, make sure your setup will be flexible enough to suit your needs years ahead. Make sure you can use your backup and rescue tools effectively and reliably on systems deployed on RAID devices. Make sure you do not create impossible setups where you have no ability to change things save for a complete reinstall.
That said, this concludes the tutorial.
Conclusion
Working with RAID is an advanced task, but it can be managed. Hopefully, this tutorial cleared up things a bit.
Alongside the knowledge you have gained on working with the GRUB bootloader and GParted partitioning software,
the RAID tutorial should give you the skills needed required to safely and with confidence wade into the waters
of Linux system administration.
In the future, we'll tackle more great stuff, including LVM, the iptables firewall and many other exciting projects. And if you have suggestions, feel free to email me.
Have fun.